- AI platforms
- Q-omics
- Smart data mining for oncology and cancer research
- NetCSSP
- Prediction of chameleon seq. and amyloid fibril formation
- Tools
- Qhelix
- Analysis of geometric arrangement
of protein helices
- QCanvas
- Fast clustering and
visualization of data
- Qsurface
- Identification of cell surface
transcriptome markers in cancers

- Smart screening for systems medicines
-
Availability of multi-level omics data such as genome, transcriptome, proteome and phosphatome data enables system-level analyses for the prediction and characterization of selective drug response on target diseases.
-
Integration of multi-level omics data with chemical or siRNA screening data on diverse biological samples is accelerating discovery studies on clinically relevant drug applications and their mode of actions.
-
For this purpose, we have constructed a smart screening platform combining technologies on computer-oriented big data mining and experimental high content screening for last several years.
-
- ▶ 1. Pan-omics data mining and screening
-
 Method development and optimization for big data analysis
Method development and optimization for big data analysis - Generate diverse patterns and hypotheses describing the association between varied drug
- response and molecular signatures such as mutation, gene or protein markers.
- Validation of target molecules and samples for the optimization of high content siRNA or
- chemical library screening
-
- ▶ 2. High throughput siRNA and chemical library screening
- Image and cell-based assay development for high content screening
- Automation and standardization of high throughput screening
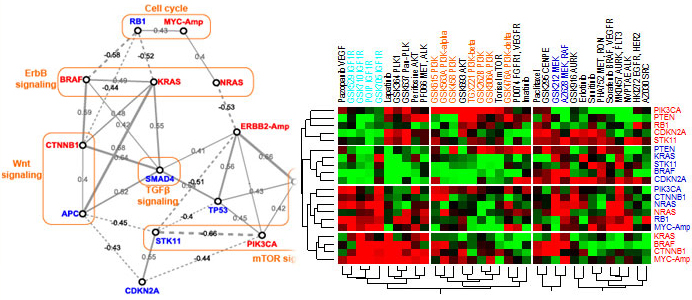
- System-level interpretation of siRNA library screening
-
- ▶ 3. Molecular modeling and drug design
- Application of machine learning algorithms for cell-based SAR studies
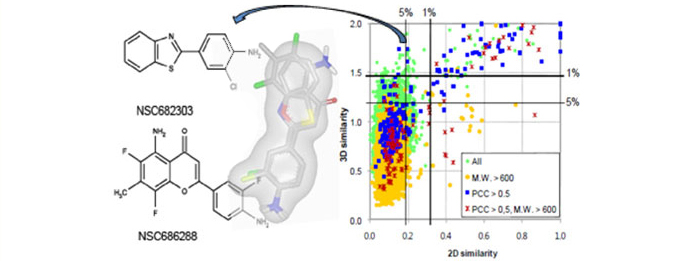
- 3D shape-based chemical analysis
- Protein and peptide sequence optimization
-